


Me and my friends we got money to spend
Plaid roadmap edition
Originally published at https://blog.thesharmas.org on March 24, 2021
Plaid is rumored to have raised a massive post-visa-breakup funding round last week. Since lending is something that I get excited about in fintech, here are some product suggestions and ways Plaid can spend that money! Want to own these ideas? Also listed as an NFT, Start bidding!
To organize our discussion, it is helpful to have a mental model of the core constituents of any lending business.

What follows below is an outline of the use cases and opportunities in each area and initial ideas on how Plaid can solve those use cases. Plaid has the opportunity to be the core provider of data to every lender on the planet. This is the north star worth shooting for.
Acquisition
The core problem to solve is – how to acquire customers with high intent and low cost?
Opportunities
Shorten the application process
This is the most obvious opportunity. Plaid’s core principle is to enable user permissioned data access. As an example, It is easier for users to remember credentials to their bank account rather than the current balance in their bank account. The entire point of application forms for lending is to gather financial data from the user. Using plaid, the user experience can be converted from a long application form to a short form that enables users to enter credentials to the places where the data is stored (bank, payroll). The lender gets the most accurate data, the customer has an extremely short application form – increase in conversion and outcomes all around.
Intent identification and triggers.
This is the more interesting opportunity. Identifying customers who need financing at the point when they need it is the holy grail of marketing. Every marketing channel used today (direct mail, performance marketing, brand marketing) is a lossy way to identify intent. The credit bureaus offer a product called Triggers which is a great way to attack this problem. However, the trigger product isn’t real-time.
Plaid has an opportunity to make this a high-fidelity activity. Let’s walk through an example. A lot of growth in the online lending space is in the refinance segment. As online platforms (theoretically) can offer cheaper rates for the same credit risk, refinancing a customer’s existing debt is a great way to capture market share. This is Lending Club’s playbook, its main business is Credit card refi. Sofi followed the same playbook with student loan refi. Since Plaid has real-time access to bank data, it can provide a real-time trigger to its lending customers that a consumer or business has just taken out a loan. This is possible using the loan repayment transaction that shows up in the bank data. Plaid has a smaller version of the product in the liabilities endpoint but it only returns loans originated by the bank. By using bank transaction data this trigger would capture all repayments for all loans which is a wider and complete net. Lenders would pay $$$ for this trigger!
Underwriting
The core problem to solve is – Should I reject or accept this customer and at what price? Underwriting is the heart of the business and it is all about the data!
Opportunities
Provide aggregates
The major input to any credit model is data with the output being a decision. There are always at a minimum two models in the underwriting process. At the top of the funnel, there is a boundary aka pre-qualification model that takes a small set of inputs to decide if this entity is even eligible for a loan. This helps keeps costs low for underwriting and also helps immensely with customer experience as it is better to provide a negative decision upfront. Golden product rule- Don’t keep the customer hanging and facing decision anxiety. Once the customer passes pre-qual, more data is collected to run the full underwriting model. The input data is aggregated into simple ratios such as asset coverage, debt coverage, and repayment performance. These ratios are then used by a human or an automated credit model to decide to accept or reject. To have the correct aggregates you need to have the right data, the freshest data, and the cleanest data. Executing this at scale entails creating and maintaining a complex data pipeline. This complexity makes credit policy prototyping a hard task and slows down the lender’s ability to react to macro changes in the economy. Imagine not being able to adjust your credit policies as Covid hit – these macro changes can devastate a lending business.
Plaid has all of this data! An opportunity exists to provide financial aggregates to lenders at a fine-grained entity level (a single consumer, a single business). Plaid being the source of the aggregate data is in a better position to maintain cleanliness and freshness since everything is user permissioned. This makes the pipeline process of building credit models at the lender super easy as plaid is the source for the aggregates. In addition to data aggregates plaid could easily provide credit policy related items (Examples: # of current loans, industry classification) that are used by lenders to model and check portfolio concentration limits
Backtesting
An under-appreciated opportunity exists in the backtest area of underwriting. When a credit model rejects an applicant, it is making a prediction based on what it knows today. It believes that this application may have a high rate of default in the future that is outside the current risk appetite- thus we are going to reject them. However, this is just a prediction based on past data and hence it’s never 100% accurate. It is best practice for credit teams to look at the actual performance of the pool of rejected applicants and measure the error rate of the model prediction vs actual results. This is a key step in optimizing the credit model. However, this process is extremely manual and time-consuming. Most analytical teams get credit data for these rejected applicants via “refresh” files from the bureau along with other data from a lot of disparate vendors. Stitching all this data together and tying it to a single identity of your applicant is a huge pain point for credit teams.
Plaid can solve this problem! Since plaid holds the identity of the customer, it is a natural stitching point for tying all these data sources into a single customer profile. Plaid seems to be already on this path via Plaid exchange. It can enhance the single customer profile with credit data, DNB data, advertising data – the sky is the limit. Providing this stitched data to Credit teams for backtesting will be a godsend!
Loan servicing
The core problem to solve – Is this borrower going to be delinquent? The holy grail is to identify as early as possible if a borrower is going to miss a re-payment.
Opportunity
Liquidity measures
The opportunity in loan servicing is in creating and quantifying measures of liquidity. Plaid can develop a liquidity score for a consumer or a business utilizing bank data, income data, and asset data. Lenders can set thresholds and get real-time notifications when the score drops, effectively identifying a customer before they are about to miss a payment. This is a huge win for the loan servicing and collection teams as they can proactively offer support to the customer and start taking steps to bring them back to repaying the loan.
Legal and compliance and money movement
The opportunities here are pretty straightforward. There exists an opportunity to add identity verification into the shortened application process to further increase conversion. A ton has already been written about Plaid’s efforts in the money movement area as part of the VISA deal, so I’m not going to rehash it here. Plaid already has an auth and deposit switch product in this area and probably will announce native bank-to-bank movement in the near future.
What is the optimal sequencing?
The opportunity is to capture all of it, but what is the initial wedge? The largest opportunity is in the underwriting area as it is central to the business, but this is also the hardest to sell into. Underwriting orgs are very resistant to change and will prefer to stick to their current processes. Existing lenders already have the data pipelines etc set up, they are not going to want to rip it out.
The backtest area of underwriting holds the best promise for product attach. Credit teams are open to experimenting with backtests as it is a pain in the behind to run due to the complexity of the data pipeline. Most teams do not spend a lot of time spending engineering resources on creating and maintaining a data pipeline for backtests, so plaid providing a clean data set that is matched up with the loan book is a super easy sell.
Loan servicing and Acquisition are the most optimal initial wedges. With the covid situation, in the near term, loan performance is already a hot topic with every lender. This is also an area where there isn’t a lot of innovation. There will be a natural pull towards a quick and easy to implement solution and thus an easy sell into the organization. Acquisition is always going to be one of the top priorities for any lending org. Both these new products are also derivatives of Plaid’s existing data models so the feedback cycle to develop these products promises to be short and quick.
These wedges are like a pincer move into the core underwriting function. Once Plaid has entered into the lending organization via acquisition and loan servicing, underwriting is not too far off and once you have underwriting you have the whole business.
What is the big big big big bet?
Most of what has been described above apply to how the world looks today. But what does the future hold?
Plaid can go further and get to the holy grail that no lender has been able to get to – the holy grail of accurate cash flow modeling. At the end of the day, a lender is trying to figure out if there are enough cashflows in the entity to pay back the loan. Looking at tax returns, looking at payroll stubs, looking at credit score is all a proxy to cash flow modeling. Plaid has the data to do this! They have bank data, they have income data – they can model this out. Based on this cashflow model Plaid can start predicting when a consumer or business needs credit to bridge their expenses and thus provide a predictive lendable score. As a lender, I would love this – getting to the consumer right before the point where they need credit!
A natural extension of the cash flow modeling is pre-approvals. Plaid has a network of consumer apps that use Plaid as the underlying bank data infrastructure. I’ve talked about how the future of finance is embedded and embedded lending is the future. So let us flip the model. Instead of customers applying to lenders and getting a decision, lenders pre-approve customers and push loans to them via these consumers’ apps. Customers don’t need to apply anymore, it’s all pushed to them from applications that they use every day. Moreover, consumers have explicitly given their consent to these apps to aggregate and use their data. This is an opt-in model which is way way better than being pushed advertising to get a loan that a) is a hassle to apply for b) you might not need at all!

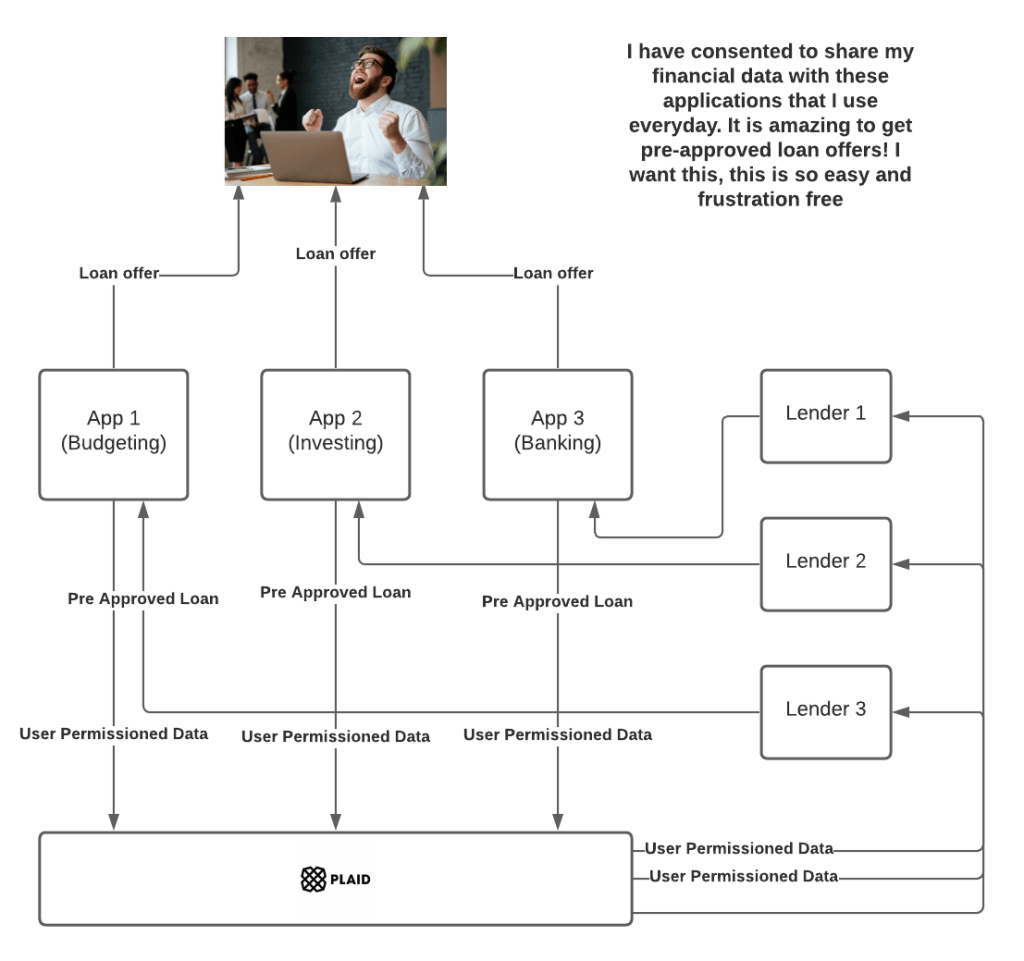
This model also aligns incentives between the consumer, the consumer application, and the lender. The consumer gets a loan effortlessly with the lowest friction, which they explicitly consented to. The Lender gets standardized real-time cashflow/financial data, a low cost of acquisition, and amazing conversion due to the ability to pre-approve. The consumer app gets to monetize their users by providing the users a product that they need and increase retention of those users. It’s a win-win-win.
When Plaid executes on all these ideas (which I’m sure they will), Plaid will become the de-facto lending firmware for the internet.